
Talk to your Mac, query your docs, no cloud required.
RCLI is an on-device voice AI for macOS. A complete STT + LLM + TTS + VLM pipeline running natively on Apple Silicon — 40 macOS actions via voice, local RAG over your documents, on-device vision (camera & screen analysis), sub-200ms end-to-end latency. No cloud, no API keys.
Powered by MetalRT, a proprietary GPU inference engine built by RunAnywhere, Inc. specifically for Apple Silicon.
Demo
Real-time screen recordings on Apple Silicon — no cloud, no edits, no tricks.
|
Voice Conversation Talk naturally — RCLI listens, understands, and responds on-device. 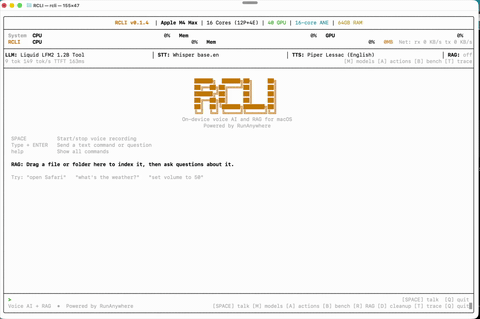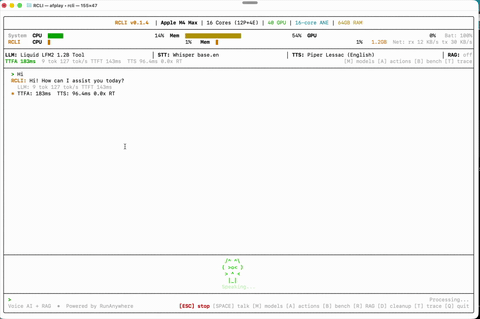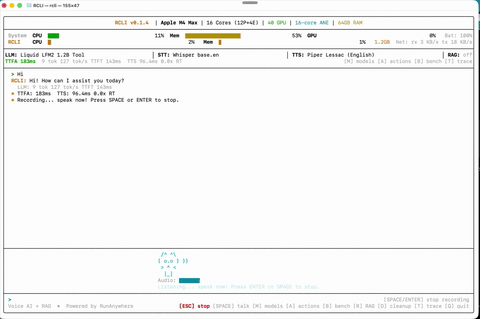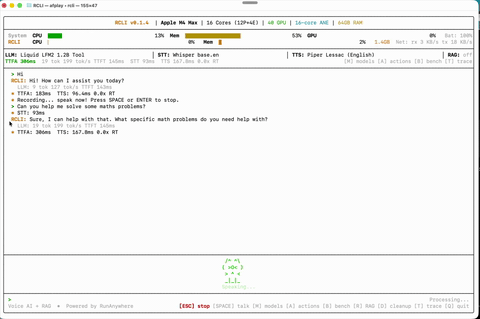
Click for full video with audio |
App Control Control Spotify, adjust volume — 38 macOS actions by voice. 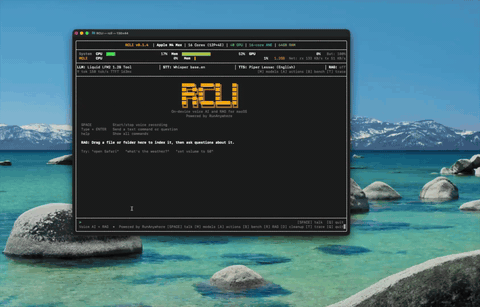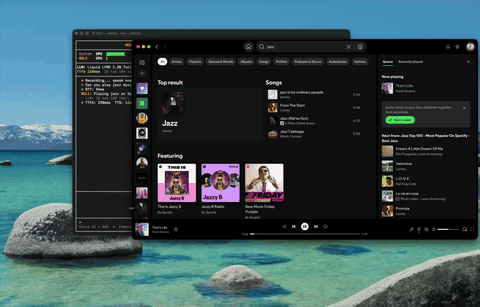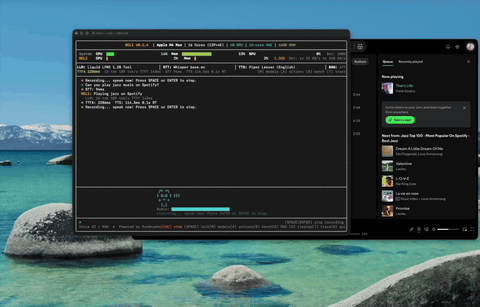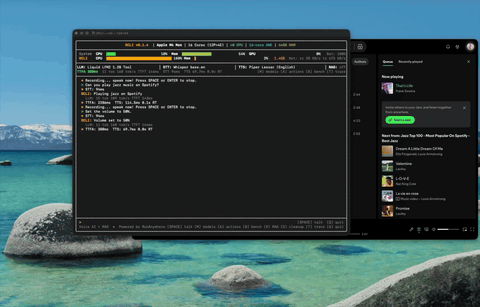
Click for full video with audio |
|
Models Browse models, hot-swap LLMs — all from the TUI. 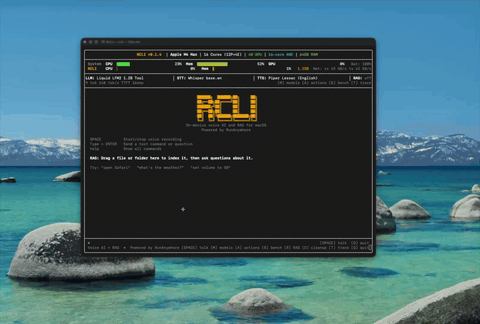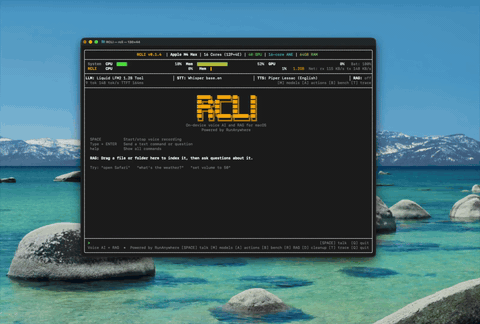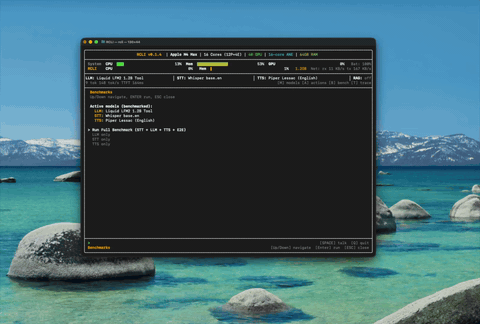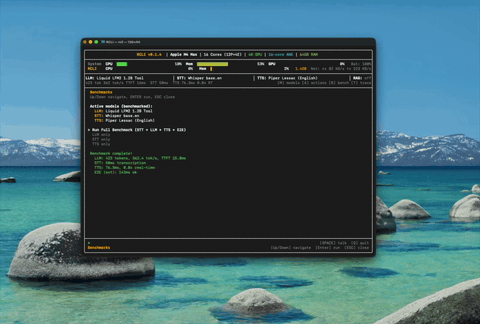
Click for full video with audio |
Document Intelligence (RAG) Ingest docs, ask questions by voice — ~4ms hybrid retrieval. 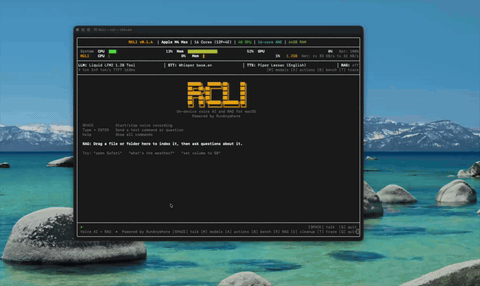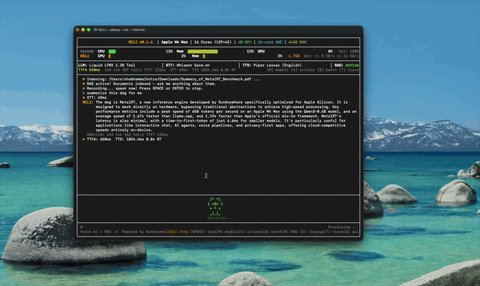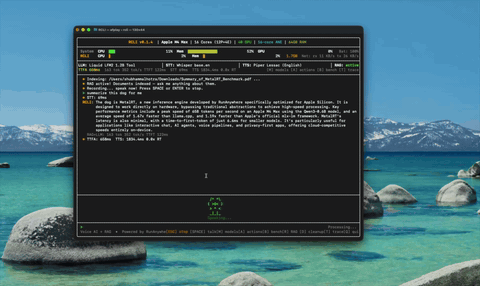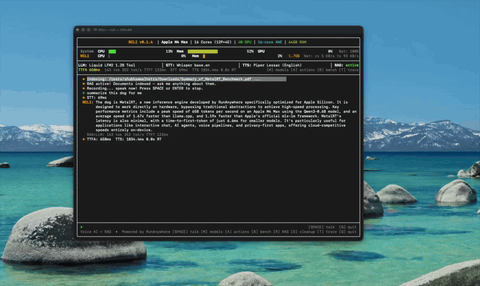
Click for full video with audio |
Install
[IMPORTANT] Requires macOS 13+ on Apple Silicon. MetalRT engine requires M3 or later. M1/M2 Macs fall back to llama.cpp automatically.
One command:
curl -fsSL https://raw.githubusercontent.com/RunanywhereAI/RCLI/main/install.sh | bash
Or via Homebrew:
brew tap RunanywhereAI/rcli https://github.com/RunanywhereAI/RCLI.git
brew install rcli
rcli setup # required — downloads AI models (~1GB, one-time)
Upgrade to latest:
brew update
brew upgrade rcli
Troubleshooting: SHA256 mismatch or stale version
If `brew install` or `brew upgrade` fails with a checksum error: ```bash # Force-refresh the tap to pick up the latest formula cd $(brew --repo RunanywhereAI/rcli) && git fetch origin && git reset --hard origin/main brew reinstall rcli ``` If that doesn't work, clean re-tap and clear the download cache: ```bash brew untap RunanywhereAI/rcli rm -rf "$(brew --cache)/downloads/"*rcli* brew tap RunanywhereAI/rcli https://github.com/RunanywhereAI/RCLI.git brew install rcli rcli setup ```Quick Start
rcli # interactive TUI (push-to-talk + text)
rcli listen # continuous voice mode
rcli ask "open Safari" # one-shot command
rcli ask "play some jazz on Spotify"
rcli vlm photo.jpg "what's in this image?" # vision analysis
rcli camera # live camera VLM
rcli screen # screen capture VLM
rcli metalrt # MetalRT GPU engine management
rcli llamacpp # llama.cpp engine management
Benchmarks
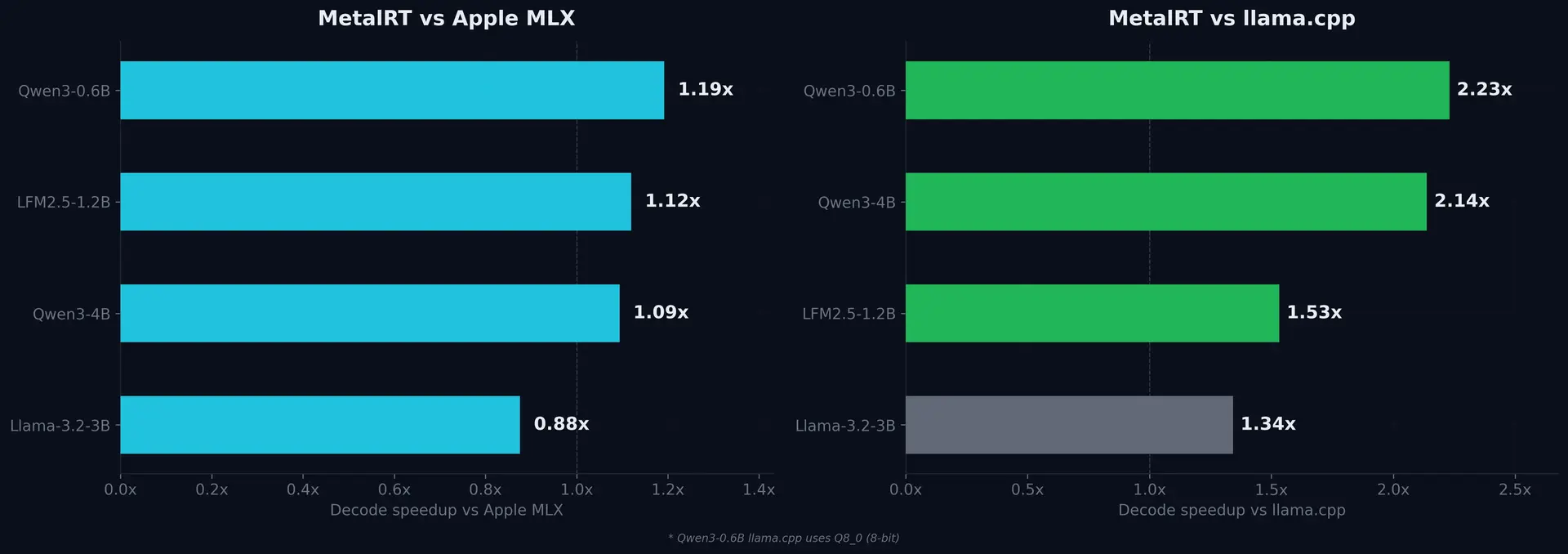
MetalRT decode throughput vs llama.cpp and Apple MLX on Apple M3 Max
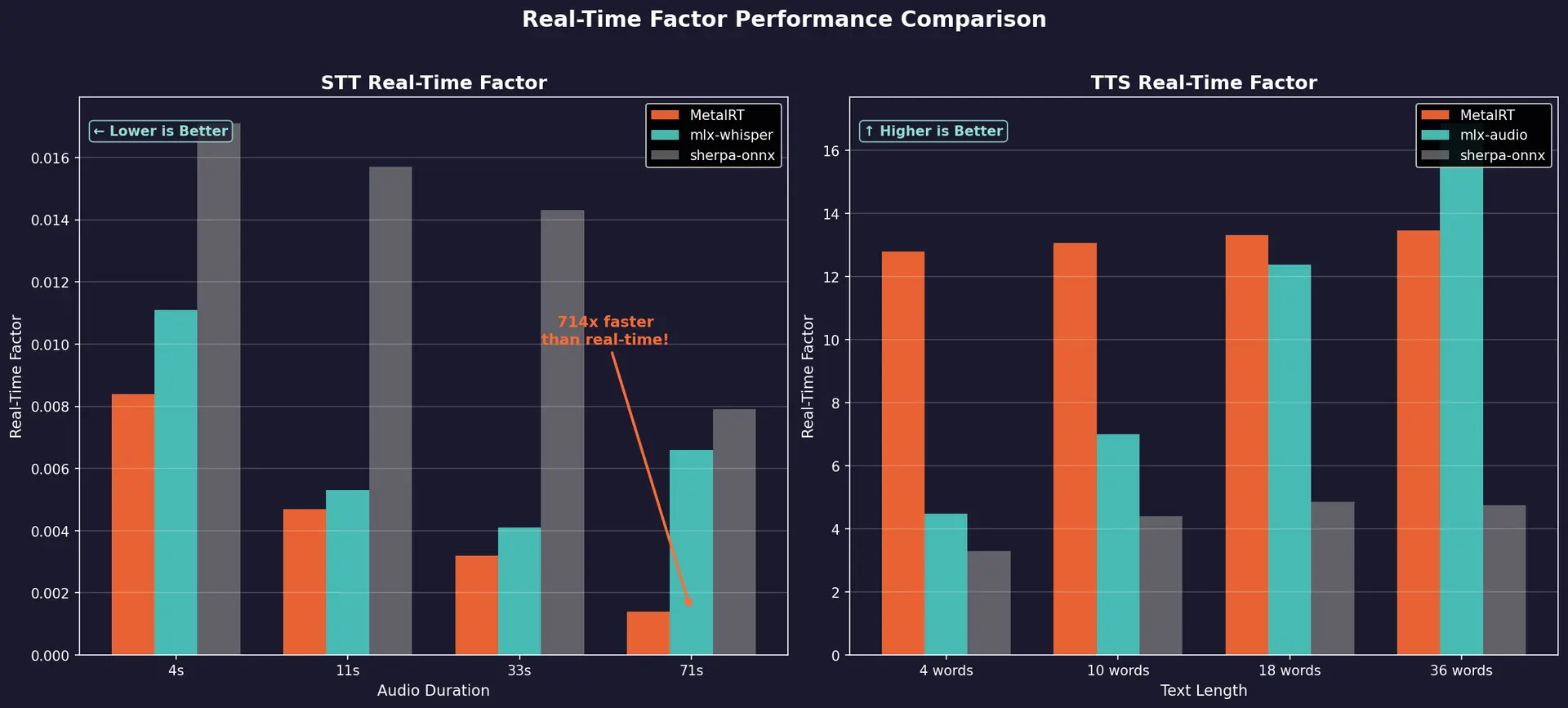
STT and TTS real-time factor — lower is better. MetalRT STT is 714x faster than real-time.
For More info :
- https://www.runanywhere.ai/blog/metalrt-fastest-llm-decode-engine-apple-silicon
- https://www.runanywhere.ai/blog/metalrt-speech-fastest-stt-tts-apple-silicon
- https://www.runanywhere.ai/blog/fastvoice-on-device-voice-ai-pipeline-apple-silicon
Features
Voice Pipeline
A full STT + LLM + TTS pipeline running on Metal GPU with three concurrent threads:
- VAD — Silero voice activity detection
- STT — Zipformer streaming + Whisper / Parakeet offline
- LLM — Qwen3 / LFM2 / Qwen3.5 with KV cache continuation and Flash Attention
- TTS — Double-buffered sentence-level synthesis (next sentence renders while current plays)
- Tool Calling — LLM-native tool call formats (Qwen3, LFM2, etc.)
- Multi-turn Memory — Sliding window conversation history with token-budget trimming
Vision (VLM)
Analyze images, camera captures, and screen regions using on-device vision-language models. VLM runs on the llama.cpp engine via Metal GPU — no cloud.
- Image Analysis —
rcli vlm photo.jpg "describe this"for single-image queries - Camera — Press V in the TUI or run
rcli camerafor live camera analysis - Screen Capture — Press S in the TUI or run
rcli screento analyze screen regions - Models — Qwen3 VL 2B, Liquid LFM2 VL 1.6B, SmolVLM 500M — download on demand via
rcli models vlm
Note: VLM is currently available on the llama.cpp engine. MetalRT VLM support is coming soon.
40 macOS Actions
Control your Mac by voice or text. The LLM routes intent to actions executed locally via AppleScript and shell commands.
| Category | Examples |
|---|---|
| Productivity | create_note, create_reminder, run_shortcut |
| Communication | send_message, facetime_call |
| Media | play_on_spotify, play_apple_music, play_pause, next_track, set_music_volume |
| System | open_app, quit_app, set_volume, toggle_dark_mode, screenshot, lock_screen |
| Web | search_web, search_youtube, open_url, open_maps |
Run rcli actions to see all 40, or toggle them on/off in the TUI Actions panel.
Tip: If tool calling feels unreliable, press X in the TUI to clear the conversation and reset context. With small LLMs, accumulated context can degrade tool-calling accuracy — a fresh context often fixes it.
RAG (Local Document Q&A)
Index local documents, query them by voice. Hybrid vector + BM25 retrieval with ~4ms latency over 5K+ chunks. Supports PDF, DOCX, and plain text.
rcli rag ingest ~/Documents/notes
rcli ask --rag ~/Library/RCLI/index "summarize the project plan"
Interactive TUI
A terminal dashboard with push-to-talk, live hardware monitoring, model management, and an actions browser.
| Key | Action |
|---|---|
| SPACE | Push-to-talk |
| V | Camera — capture and analyze with VLM |
| S | Screen — capture and analyze a screen region with VLM |
| M | Models — browse, download, hot-swap LLM/STT/TTS/VLM |
| A | Actions — browse, enable/disable macOS actions |
| R | RAG — ingest documents |
| X | Clear conversation and reset context |
| T | Toggle tool call trace |
| ESC | Stop / close / quit |
MetalRT GPU Engine
MetalRT is a high-performance GPU inference engine built by RunAnywhere, Inc. specifically for Apple Silicon. It delivers the fastest on-device inference for LLM, STT, and TTS — up to 550 tok/s LLM throughput and sub-200ms end-to-end voice latency.
Apple M3 or later required. MetalRT uses Metal 3.1 GPU features available on M3, M3 Pro, M3 Max, M4, and later chips. M1/M2 support is coming soon. On M1/M2, RCLI automatically falls back to the open-source llama.cpp engine.
MetalRT is automatically installed during rcli setup (choose “MetalRT” or “Both”). Or install separately:
rcli metalrt install
rcli metalrt status
Supported models: Qwen3 0.6B, Qwen3 4B, Llama 3.2 3B, LFM2.5 1.2B (LLM) · Whisper Tiny/Small/Medium (STT) · Kokoro 82M with 28 voices (TTS)
MetalRT is distributed under a proprietary license. For licensing inquiries: founder@runanywhere.ai
Supported Models
RCLI supports 20+ models across LLM, STT, TTS, VLM, VAD, and embeddings. All run locally on Apple Silicon. Use rcli models to browse, download, or switch.
LLM: LFM2 1.2B (default), LFM2 350M, LFM2.5 1.2B, LFM2 2.6B, Qwen3 0.6B, Qwen3.5 0.8B/2B/4B, Qwen3 4B
STT: Zipformer (streaming), Whisper base.en (offline, default), Parakeet TDT 0.6B (~1.9% WER)
TTS: Piper Lessac/Amy, KittenTTS Nano, Matcha LJSpeech, Kokoro English/Multi-lang
VLM: Qwen3 VL 2B, Liquid LFM2 VL 1.6B, SmolVLM 500M — on-demand download via rcli models vlm (llama.cpp engine only)
Default install (rcli setup): ~1GB — LFM2 1.2B + Whisper + Piper + Silero VAD + Snowflake embeddings. VLM models are downloaded on demand.
rcli models # interactive model management
rcli models vlm # download/manage VLM models
rcli upgrade-llm # guided LLM upgrade
rcli voices # browse and switch TTS voices
rcli cleanup # remove unused models
Build from Source
CPU-only build using llama.cpp + sherpa-onnx (no MetalRT):
git clone https://github.com/RunanywhereAI/RCLI.git && cd RCLI
bash scripts/setup.sh
bash scripts/download_models.sh
mkdir -p build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
cmake --build . -j$(sysctl -n hw.ncpu)
./rcli
All dependencies are vendored or CMake-fetched. Requires CMake 3.15+ and Apple Clang (C++17).
CLI Reference
``` rcli Interactive TUI (push-to-talk + text + trace) rcli listen Continuous voice mode rcli askBuilt by RunAnywhere, Inc.